正则表达式 - 修饰符(标记)
正则表达式修饰符(也称为模式修饰符或标记)是用于改变正则表达式匹配行为的特殊指令。
标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略。
标记不写在正则表达式里,标记位于表达式之外,格式如下:
/pattern/flags
常用修饰符
下表列出了正则表达式常用的修饰符:
1. i (ignore case) - 忽略大小写
-
使匹配不区分大小写
-
示例:
/abc/i可以匹配 "abc", "Abc", "ABC" 等 -
支持语言:几乎所有正则表达式实现(JavaScript、PHP、Python等)
2. g (global) - 全局匹配
-
查找所有匹配项,而不是在第一个匹配后停止
-
示例:在字符串 "ababab" 中,
/ab/g会匹配所有三个 "ab" -
支持语言:JavaScript、PHP等
3. m (multiline) - 多行模式
-
改变
^和$的行为,使其匹配每行的开头和结尾,而不仅是整个字符串的开头和结尾 -
示例:在多行字符串中,
/^abc/m会匹配每行开头的 "abc" -
支持语言:JavaScript、PHP、Python、Perl等
4. s (single line/dotall) - 单行模式
-
使点号
.匹配包括换行符在内的所有字符 -
在JavaScript中称为"dotall"模式,使用
/s修饰符 -
示例:
/a.b/s可以匹配 "a\nb" -
支持语言:PHP、Perl、Python(作为
re.DOTALL)、JavaScript(ES2018+)
5. u (unicode) - Unicode模式
-
启用完整的Unicode支持
-
正确处理UTF-16代理对和Unicode字符属性
-
示例:
/\p{Script=Greek}/u可以匹配希腊字母 -
支持语言:JavaScript、PHP等
6. y (sticky) - 粘性匹配
-
从目标字符串的当前位置开始匹配(使用
lastIndex属性) -
类似于
^锚点,但针对的是匹配的起始位置 -
示例:在JavaScript中,
/a/y会从lastIndex开始匹配 "a" -
支持语言:JavaScript
7. x (extended) - 扩展模式
-
忽略模式中的空白和注释,使正则表达式更易读
-
示例:在PHP中,
/a b c/x等同于/abc/ -
支持语言:PHP、Perl、Python(作为
re.VERBOSE)
g 修饰符
g 修饰符可以查找字符串中所有的匹配项:
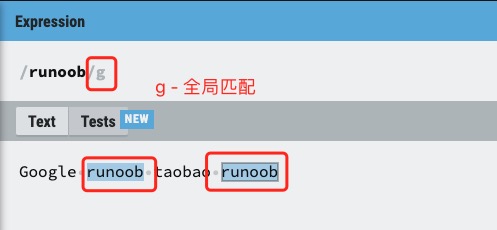
实例
在字符串中查找 "runoob":
尝试一下 »
i 修饰符
i 修饰符为不区分大小写匹配,实例如下:
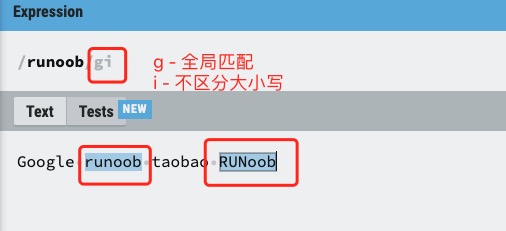
实例
在字符串中查找 "runoob":
尝试一下 »
m 修饰符
m 修饰符可以使 ^ 和 $ 匹配一段文本中每行的开始和结束位置。
g 只匹配第一行,添加 m 之后实现多行。

以下实例字符串中使用 \n 来换行:
实例
在字符串中查找 "runoob":
尝试一下 »
s 修饰符
默认情况下的圆点 . 是 匹配除换行符 \n 之外的任何字符,加上 s 之后, . 中包含换行符 \n。
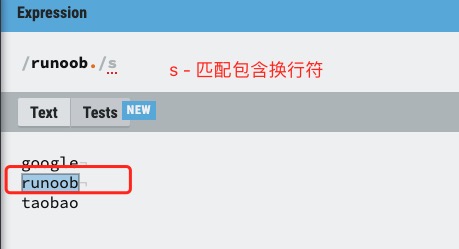
s 修饰符实例如下:
实例
在字符串中查找:
尝试一下 »
扩展说明
语言特定修饰符补充表:
| 语言 | 特有修饰符 | 描述 |
|---|---|---|
| PHP | A |
锚定模式到字符串开头 |
D |
$仅匹配字符串结尾(不包括结尾换行) |
|
U |
反转量词的贪婪性(使所有量词变为非贪婪) | |
| Python | re.A |
使\w,\W,\b,\B等仅匹配ASCII字符 |
re.L |
根据本地化设置确定\w,\W等的含义 |
|
| JS(ES2022) | d |
为匹配结果生成indices属性(包含匹配位置的起止索引) |
修饰符组合示例表:
| 组合 | 效果 |
|---|---|
gi |
全局匹配+忽略大小写(如查找所有格式的"email"单词) |
ims |
忽略大小写+多行模式+点号匹配换行符(常用于日志分析) |
gu |
全局匹配+Unicode支持(如查找所有Unicode表情符号) |
内联修饰符表(PCRE/Perl风格):
| 语法 | 作用范围 | 示例 |
|---|---|---|
(?i) |
启用忽略大小写 | a(?i)bc → 匹配 "aBc"、"aBC" |
(?-i) |
禁用忽略大小写 | a(?i)b(?-i)c → 只匹配 "aBc" |
(?i:...) |
仅对括号内生效 | a(?i:b)c → 匹配 "aBc"、"abc" |
注意:不同语言对修饰符的实现可能存在差异,建议使用时参考具体语言的文档。

点我分享笔记